我的业务连续性与韧性方法论——从”体系是否存在”到”系统会不会失控”
一句话立场: 我不纠结于业务连续性管理(BCM)还是运营韧性(OR)。我真正关心的只有一件事:在真实中断与高度不确定性的条件下,企业是否还能持续交付、避免失控。
一、起点:我为什么重新思考业务连续性
我最初深入业务连续性,并不是从标准或体系开始的,而是源于一个极其朴素的问题:如果关键业务突然中断,企业是否还能在压力下保持可控,而不是迅速失控?
这个问题看似只是表述上的变化,但它实际上标志着我对业务连续性理解的一个重要转向:连续性关注的从来不只是”能不能恢复”,而是在压力不断累积的过程中,组织是否会走向失控。
此后,我系统学习了BCM的各类标准、方法与最佳实践,也深度参与过多次体系建设、评估与演练。这些工作是有价值的——它们帮助许多组织从”完全没有准备”,走向”至少看起来是有准备的”。
但随着我接触和反思越来越多真实发生的中断事件——无论是核心系统升级失败、大范围极端天气、勒索软件攻击,还是关键供应商断供——一种越来越清晰、也越来越不安的感受浮现出来:很多组织并不是”没有BCM”,而是在真正面对压力时,这套BCM并不好用。
这让我重新追问一个更根本的问题:BCM的局限,究竟是因为”我们做得还不够多”,还是因为”我们一开始就问错了问题”?
二、我不纠结BCM还是OR,只纠缠问题本身
在这些年的实践中,我对”BCM vs OR”之类的概念之争毫无兴趣。
对企业而言,真正重要的从来不是名称,而是两个非常现实的判断:这个方法,能不能解决我正面对的问题?在关键时刻,它能不能帮助管理层做出更不容易后悔的决定?
用得上的方法,就是好方法。我之所以坚持这一判断,是因为在真实中断条件下,概念本身并不能解决问题,只有那些在高压力、不确定环境中依然有效的方法,才真正具有价值。
因此,我始终坚持”拿来主义”的态度:如果BCM在某些场景下依然有效,就继续使用;如果在新的风险条件下,其解释力和指导力明显不足,就必须引入新的视角与工具。
正是在这种实践推动下,我逐渐形成了自己对”业务连续性与韧性”的理解:韧性不是对BCM的否定,而是对”BCM体系在极端与复杂条件下是否仍然有效”的进一步追问。
三、三条思想源流:我真正借用的是”看问题的方式”
在重新思考业务连续性与韧性时,我主要受到三条研究与实践路径的影响。它们并没有构成一套统一理论,却分别回应了BCM实践中长期存在、却难以正面回答的关键问题。
1. 雅可夫·Y·海姆斯(Yacov Y. Haimes):系统工程与级联失效
海姆斯的研究让我真正意识到:风险并不只是”事件发生概率 × 损失”,而是系统结构与依赖关系在压力条件下的行为方式。
在高度耦合的现代组织中,真正致命的往往不是单点故障,而是:多重依赖关系被同时打断;冲击在不同业务、技术与组织边界之间级联放大;原本处于边缘的位置,反而成为失控的放大器。
这意味着,连续性分析的重点不应只是”哪里会出问题”,而应转向一个更关键的问题:一旦出问题,冲击会如何传播,并在哪里演变为失控?
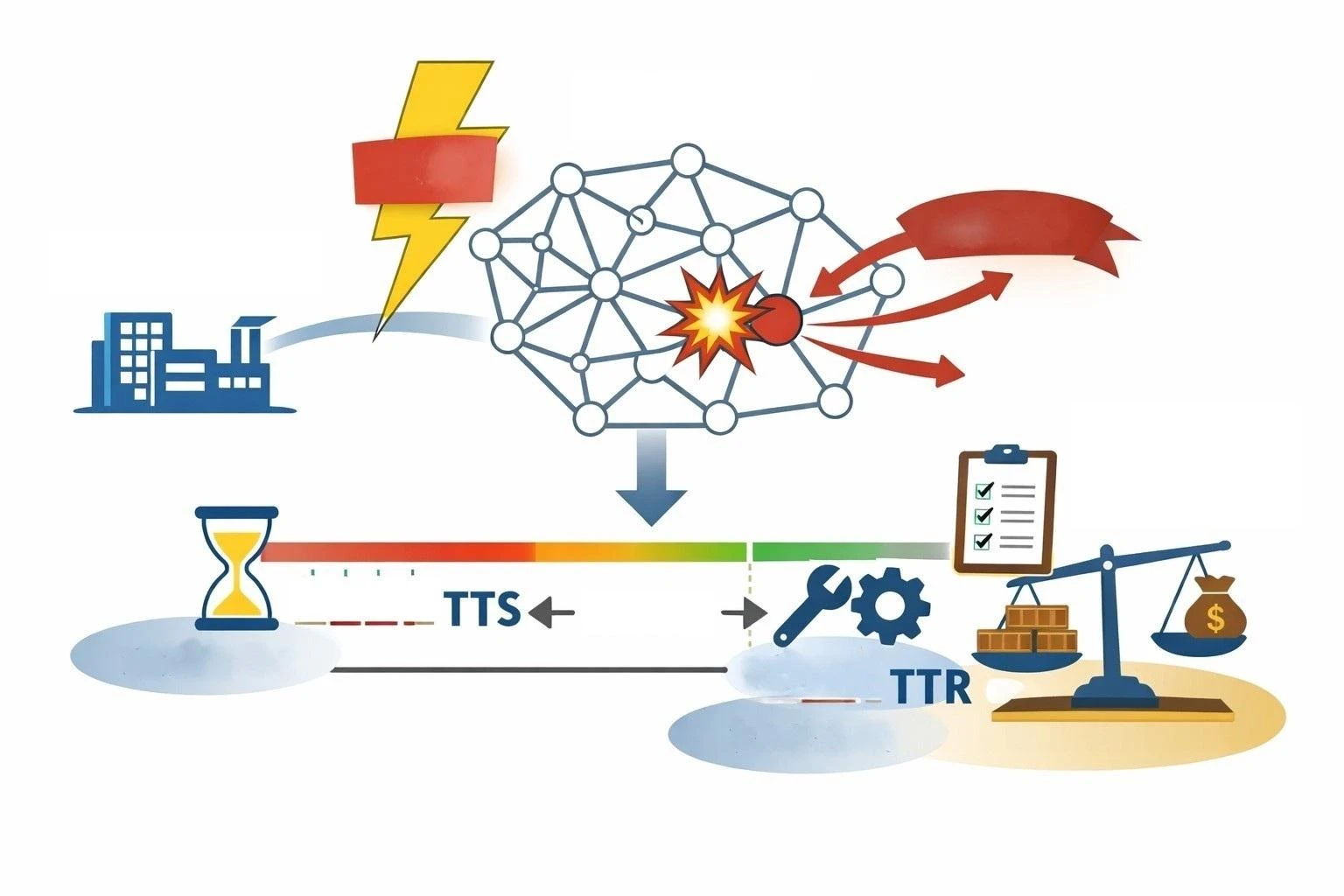
2. 大卫·辛奇-列维(David Simchi-Levi):用TTR/TTS重新定义”时间”
辛奇-列维提出的TTR/TTS框架,对我而言最大的价值并不在于量化本身,而在于它迫使组织正面回答一个极其现实、却常被回避的问题:如果恢复来不及,怎么办?
- TTR(Time to Recover):恢复到可接受状态所需的时间;
- TTS(Time to Survive):在不可接受影响出现之前,系统还能承受中断的时间。
当TTS > TTR时,恢复策略仍然成立;而当TTS ≤ TTR时,组织其实已经失去了”等待恢复”的空间,必须提前准备取舍、降级或替代方案。
在这里,“时间”不再只是管理目标,而是直接转化为生存判据。
3. 纳西姆·尼古拉斯·塔勒布(Nassim Nicholas Taleb):反幻觉,而不是更精确的预测
塔勒布的思想不断提醒我警惕一种在管理实践中极为常见、却非常危险的倾向:那些看起来非常理性、非常完整的分析,往往在真实冲击中反而会加速组织的失败。
因此,我并不追求:完美无缺的模型;精确到小数点后的概率;试图覆盖一切的情景设计。
我更关心的是:关键假设有没有被清楚地说出来;模型是否经得起”坏问题”的拷问;在高度不确定的条件下,结论是否仍然对决策有帮助。
四、方法论主干:三层结构,一个落点
综合以上思考,我形成了一套并不复杂、但高度聚焦的分析框架,其核心并非工具本身,而是问题的展开顺序。
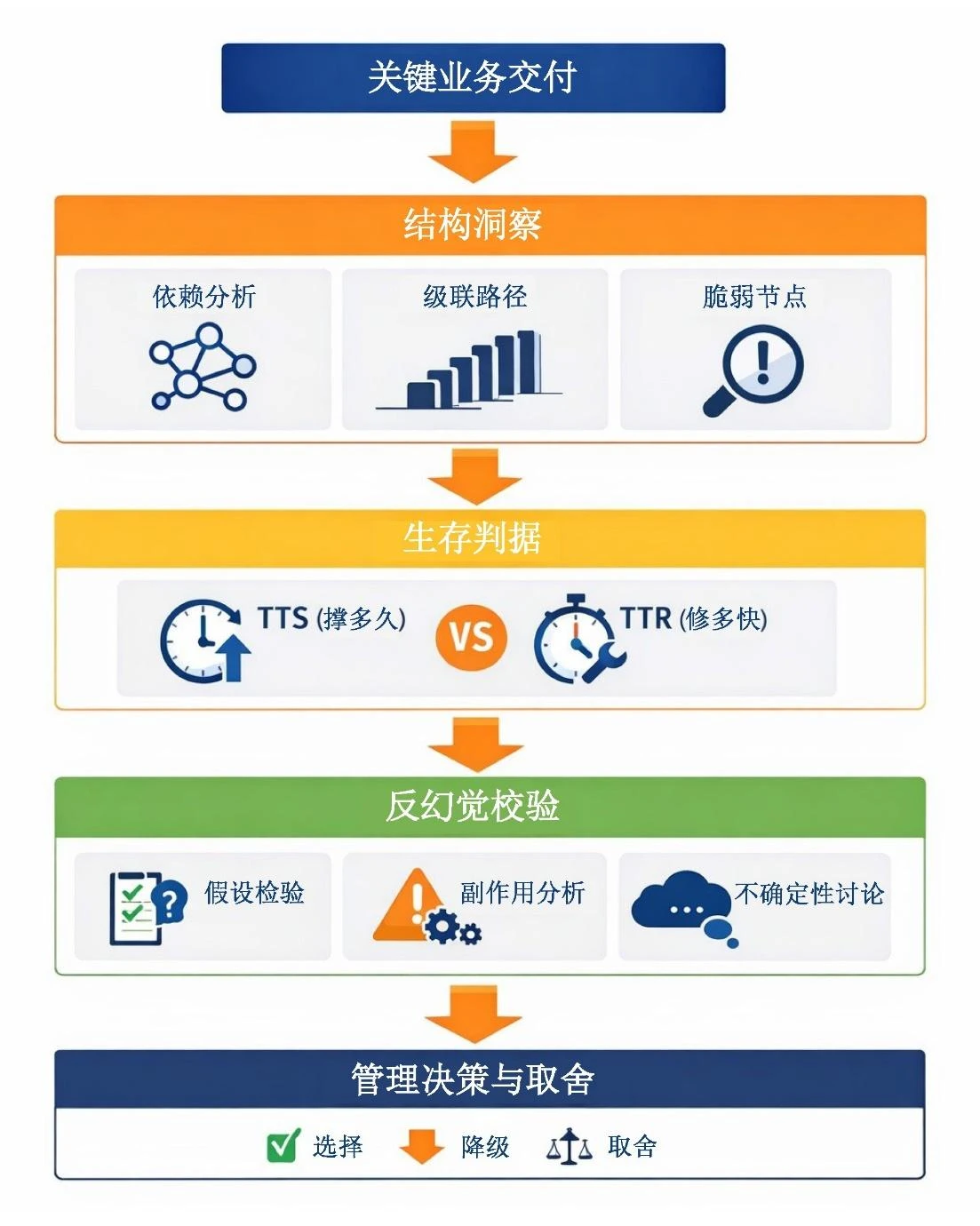
第一层:结构洞察(Systemic Insight)
这一层的目标不是简单”列清单”,而是看清结构:哪些是组织真正关键的业务交付;这些交付依赖哪些核心能力与资源;冲击可能通过哪些路径级联扩散。
它回答的核心问题是:系统究竟是如何连在一起的?
第二层:生存判据(Survivability Criteria)
在结构洞察的基础上,引入”还能撑多久 vs 多久能恢复”的判断逻辑:明确不可接受业务影响出现的时间边界;评估关键能力恢复时间的合理区间;判断组织是否仍然拥有真实的决策窗口。
这一层回答的问题是:我们是否还有时间做选择?
第三层:反幻觉校验(Anti-Illusion Check)
对所有分析结果与应对方案进行反向拷问:关键假设在极端情况下是否失效;应对策略是否引入新的系统性脆弱性;决策是否过度依赖理想化的组织行为。
这一层回答的问题是:我们是不是在用”看起来理性”的方式自我安慰?
五、关键风险情景、演练与校准:不是验证流程,而是敲打系统
在我看来,关键风险情景的真正价值,不在于讲述一个完整的故事,而在于作为一把校准工具,用来暴露并修正系统结构在压力下的真实反应。情景的意义不在于证明体系”已经存在”,而在于检验它在真实压力条件下是否仍然成立。
一个有意义的情景,必须能够迫使组织直面:多点同时失效与级联放大;决策时间被压缩、信息持续不完整;在没有完美答案的情况下,必须做出的管理取舍。
如果一次演练并不要求管理层做出真正艰难的选择,那么它对韧性的价值往往是有限的。
六、为什么我把调研当成方法论的一部分
我越来越确信:真正的问题不在文件里,而在真实事件与真实犹豫中。
正因如此,我持续通过与企业BCM负责人的调研与交流,来校验和修正自己的理解:哪些问题在不同行业中反复出现;哪些方法在实践中真正有效;哪些假设在压力条件下最容易崩塌。
如果一套方法论不能在真实实践中被敲打,它就会演变为新的形式主义。
七、为什么这个问题只会越来越重要——站在未来3–5年回看业务连续性与韧性
如果把时间拨快3–5年,再回头看今天关于业务连续性与韧性的讨论,这些问题并不会过时。相反,我越来越确信:真正变化的不是风险本身,而是企业”失控的方式”正在发生结构性转变。
风险形态本身可能同时呈现出更极端、也更复杂的特征,而在高度耦合的系统中,失控往往来得更快、更隐蔽;系统复杂度持续上升,而管理层可用于决策的时间窗口却在不断被压缩。
连续性问题,也正从传统的技术或管理议题,逐步演变为高层治理问题:当TTS ≤ TTR时,任何技术或流程层面的努力,都无法替代关于优先级、可接受损失与责任边界的管理选择。
在这样的背景下,最大的风险反而来自”错误的确定性”——那些看似严谨、实则脆弱的分析,会让组织在关键时刻坚持不该坚持的路径,错过调整窗口。
结语:方法会变,但问题不会
回到最初的问题:在关键中断情景下,企业究竟仍然处于可控状态,还是已经走向失控?
从这个角度看,韧性并不是为了避免中断本身,而是为了避免组织在中断过程中丧失判断能力与控制能力。一旦失控,技术恢复、流程完备与否都将失去意义。
BCM提供的是必要条件;而”业务连续性与韧性”这一整体视角,关注的是企业在极端条件下仍然保持可控的充分条件。
标准、模型与工具都会变化,但这个问题在未来很长一段时间内都不会消失。这正是我持续打磨这套”业务连续性与韧性方法论”的根本原因。
原文发表于公众号”王曙说” | 原文链接